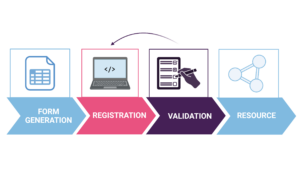
Researchers from our FAIR Data Platform published a paper on the FAIR Data Station: A platform that helps you to manage your research...
Read More
Recording, analyzing and storing data in the FAIR Data Platform
Our research platforms have different ways to identify new talent, but they are complementary and have one thing in common: They generate data....
Read More
Building your own semantic database
Finally, in this third part of our blog series on our FAIR Data Station, we describe how you can build your own Semantic...
Read More